Features
TIP
This content has been reorganized. See Core Concepts for an updated guide to Bruin's features and concepts.
Bruin is feature-packed and built to cover the majority needs of a data team, while staying extensible.
Data ingestion
Bruin has built-in data ingestion capabilities, utilizing ingestr internally. The basic idea is simple:
- you have data sources
- each source may have one or more tables/streams
- you want to load these to a destination data platform
Using Bruin, you can load data from any source into your data platforms as a regular asset.
name: shopify_raw.customers
type: ingestr
columns:
- name: id
type: integer
description: "Customer unique identifier"
primary_key: true
checks:
- name: not_null
- name: positive
parameters:
source_connection: shopify-default
source_table: customers
destination: bigquery
loader_file_format: jsonlData transformation
Bruin supports SQL, Python & R data transformations natively.
Naturally, after you ingest the data into your data warehouse/lake, you'll want to transform this data. This transformation can be a simple SQL query, or a more complicated logic written in Python or R. Bruin supports SQL, Python & R natively across many data platforms.
/* @bruin
name: chess_playground.player_summary
type: duckdb.sql
materialization:
type: table
depends:
- chess_playground.games
- chess_playground.profiles
columns:
- name: total_games
type: integer
description: "the games"
checks:
- name: positive
@bruin */
WITH game_results AS (
SELECT
CASE
WHEN g.white__result = 'win' THEN g.white__aid
WHEN g.black__result = 'win' THEN g.black__aid
ELSE NULL
END AS winner_aid,
g.white__aid AS white_aid,
g.black__aid AS black_aid
FROM chess_playground.games g
)
SELECT
p.username,
p.aid,
COUNT(*) AS total_games,
COUNT(CASE WHEN g.white_aid = p.aid AND g.winner_aid = p.aid THEN 1 END) AS white_wins,
COUNT(CASE WHEN g.black_aid = p.aid AND g.winner_aid = p.aid THEN 1 END) AS black_wins,
COUNT(CASE WHEN g.white_aid = p.aid THEN 1 END) AS white_games,
COUNT(CASE WHEN g.black_aid = p.aid THEN 1 END) AS black_games
FROM chess_playground.profiles p
LEFT JOIN game_results g
ON p.aid IN (g.white_aid, g.black_aid)
GROUP BY p.username, p.aid
ORDER BY total_games DESCRunning Python
Bruin takes the Python data development experience to the next level:
- Bruin runs assets in isolated environments: mix and match Python versions & dependencies
- It installs & manages Python versions automatically, so you don't have to have anything installed
- You can return dataframes and it uploads them to your destination
- You can run quality checks on it just as a regular asset
Bruin uses the amazing uv under the hood to abstract away all the complexity.
"""@bruin
name: tier1.my_custom_api
image: python:3.13
connection: bigquery
materialization:
type: table
strategy: merge
columns:
- name: col1
type: integer
checks:
- name: unique
- name: not_null
@bruin"""
import pandas as pd
def materialize():
items = 100000
df = pd.DataFrame({
'col1': range(items),
'col2': [f'value_new_{i}' for i in range(items)],
'col3': [i * 6.0 for i in range(items)]
})
return dfData quality checks
Bruin supports data quality checks by default, and it has a handful of built-in data quality checks. You can also write your own custom quality checks using SQL if you'd like.
Jinja templating
Bruin supports Jinja templates out of the box to reduce repetition. You can simply write any templating logic for your SQL assets and let Bruin take care of it.
{% set days = [1, 3, 7, 15, 30, 90, 120] %}
SELECT
conversion_date,
cohort_id,
{% for day_n in days %}
SUM(IFF(days_since_install < {{ day_n }}, revenue, 0)) AS revenue_{{ day_n }}_days
{% if not loop.last %},{% endif %}
{% endfor %}
FROM user_cohorts
GROUP BY 1,2This will render into the following SQL query:
SELECT
conversion_date,
cohort_id,
SUM(IFF(days_since_install < 1, revenue, 0)) AS revenue_1_days,
SUM(IFF(days_since_install < 3, revenue, 0)) AS revenue_3_days,
SUM(IFF(days_since_install < 7, revenue, 0)) AS revenue_7_days,
SUM(IFF(days_since_install < 15, revenue, 0)) AS revenue_15_days,
SUM(IFF(days_since_install < 30, revenue, 0)) AS revenue_30_days,
SUM(IFF(days_since_install < 90, revenue, 0)) AS revenue_90_days,
SUM(IFF(days_since_install < 120, revenue, 0)) AS revenue_120_days
FROM user_cohorts
GROUP BY 1,2Secrets management
Bruin allows you to define all of your credentials in a gitignored file called .bruin.yml, and it takes care of injecting secrets into your assets as environment variables automatically. You can define multiple environments, run the same asset against your staging or prod environments.
"""@bruin
name: tier1.my_custom_api
secrets:
- key: MY_SNOWFLAKE_CONN
@bruin"""
import os
import json
snowflake_creds = json.loads(os.environ["MY_SNOWFLAKE_CONN"])
# do whatever you want from here onVS Code extension
Bruin has an open-source VS Code extension that allows you to visually work on your data pipelines. It has a local data catalog, query rendering, lineage, running & backfilling pipelines and more.
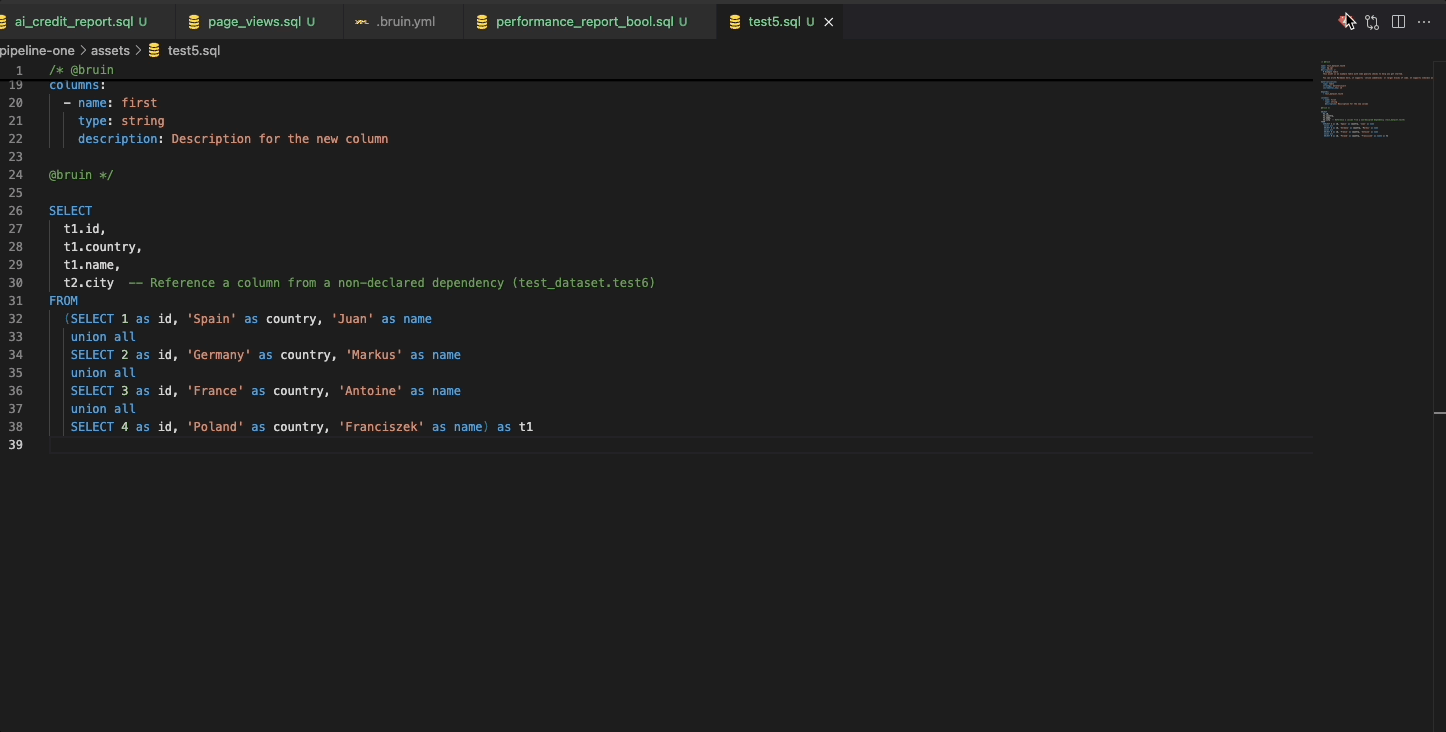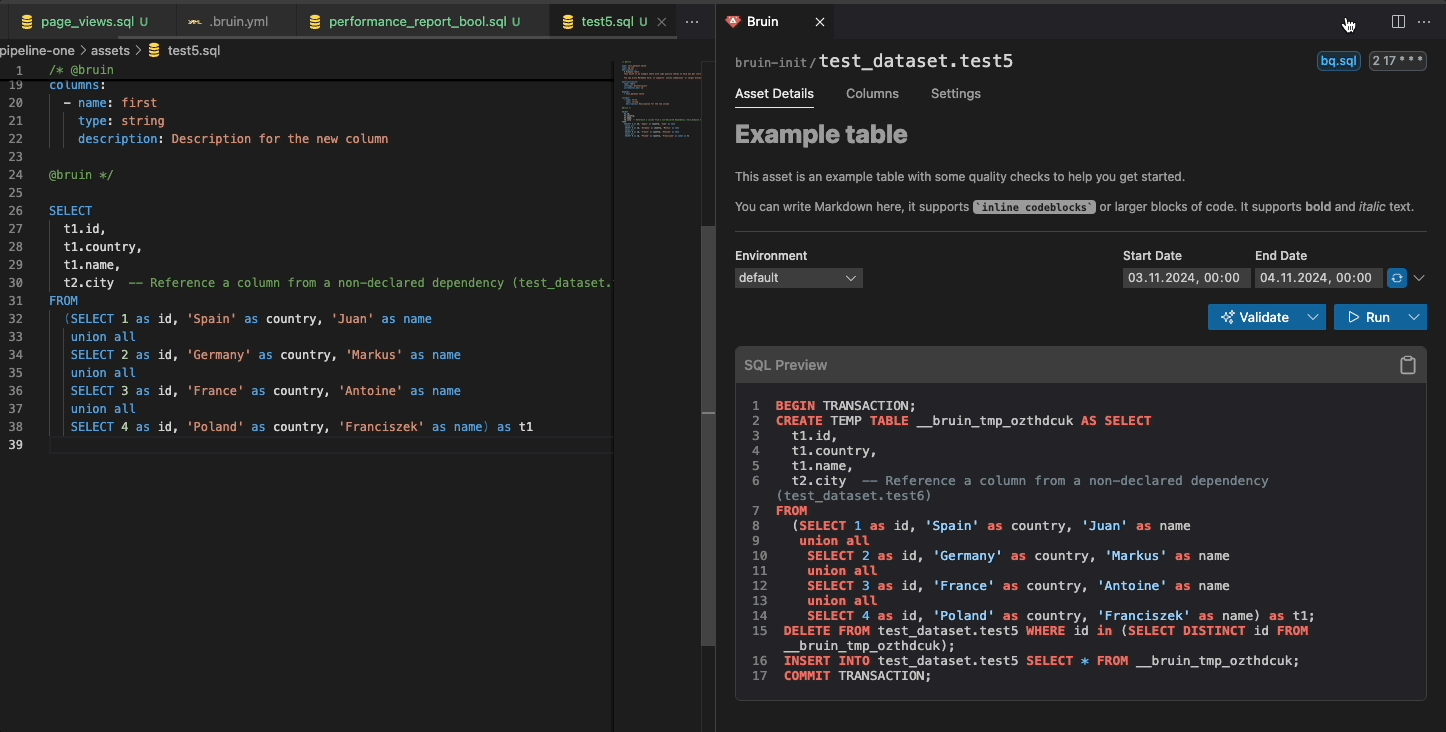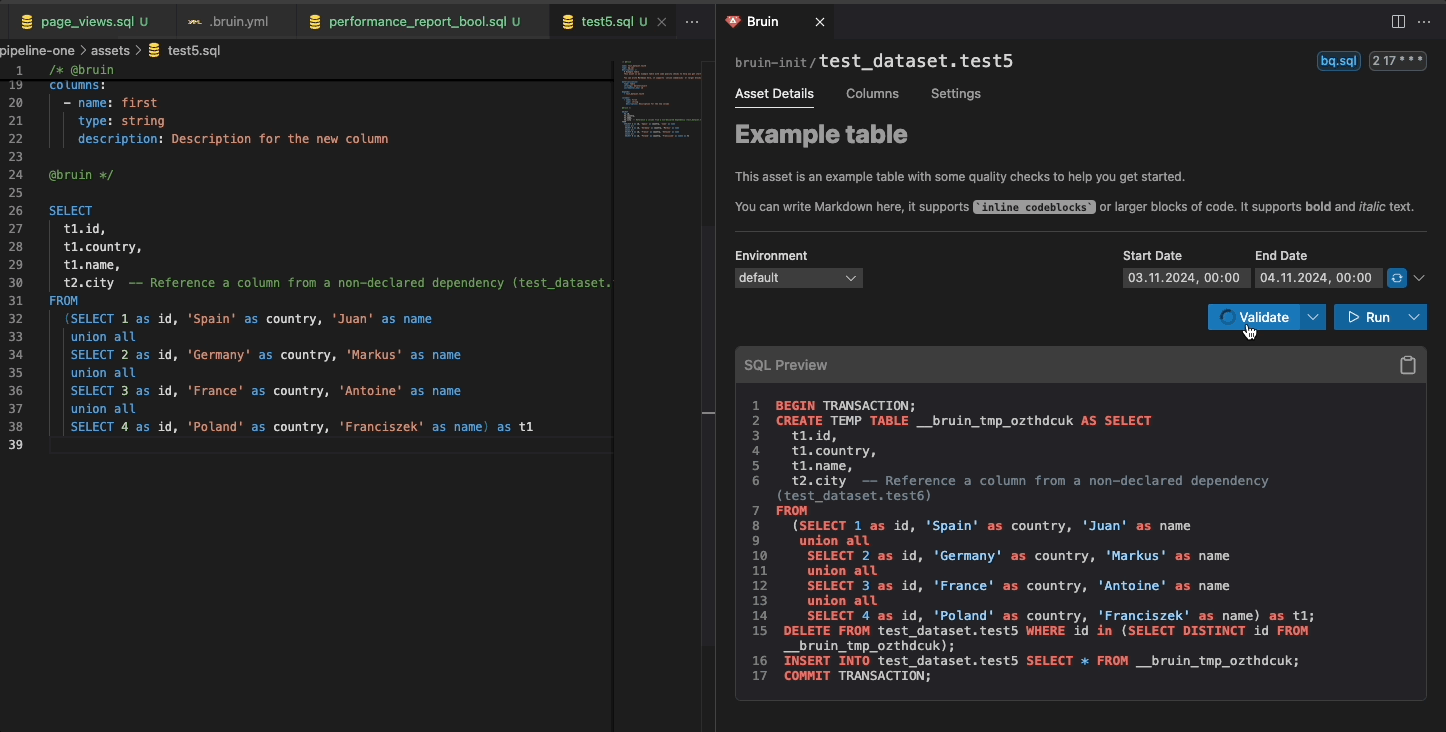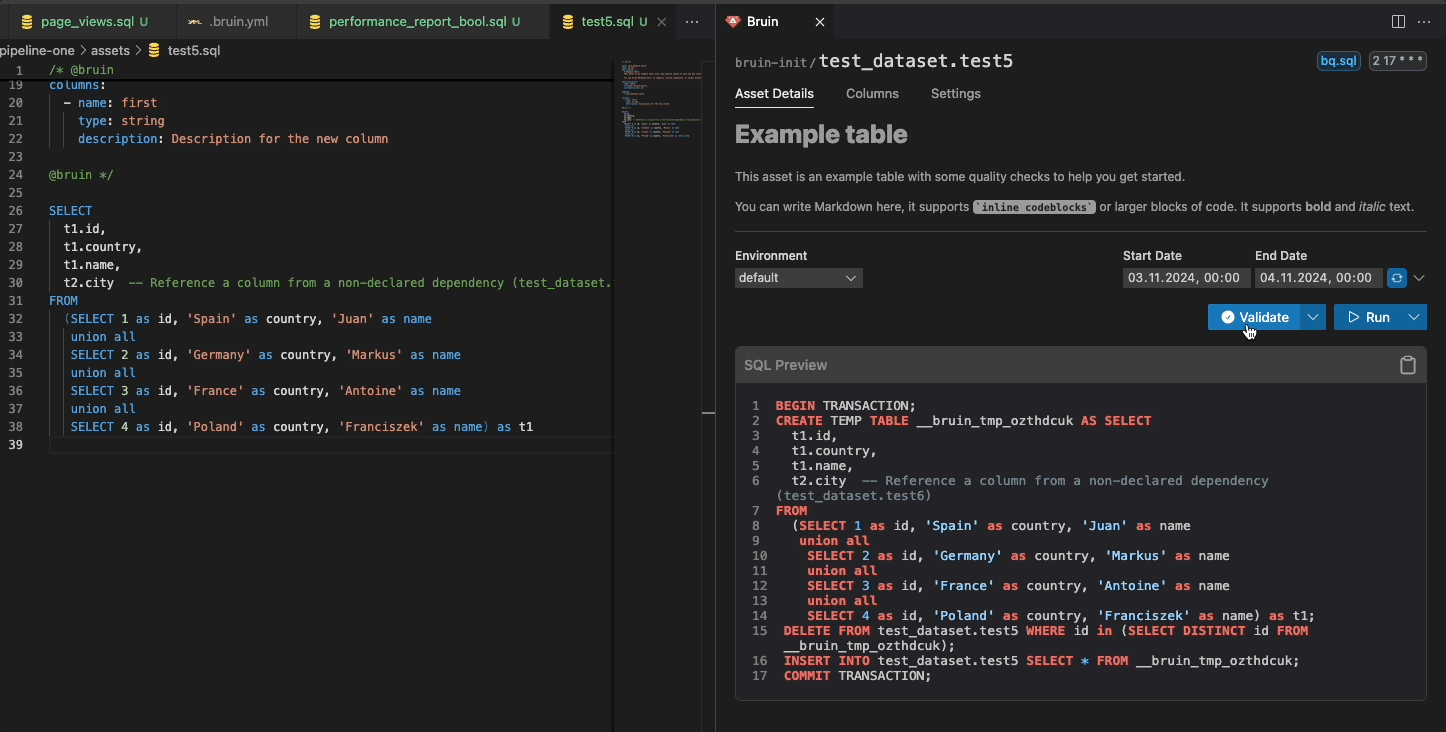
Glossaries
Bruin focuses on enabling independent teams designing independent data products. These products ought to be built and developed independently, while all working towards a cohesive data strategy. Different teams have the same name for different concepts, and aligning on these concepts are a crucial part of building successful data products.
In order to align on different teams on building on a shared language, Bruin has a feature called "glossary".
Glossaries allow:
- defining a shared language across teams/projects/pipelines
- reducing repetition for documentation and metadata
entities:
Customer:
description: Customer is an individual/business that has registered on our platform.
attributes:
ID:
type: integer
description: The unique identifier of the customer in our systems.
Email:
type: string
description: the e-mail address the customer used while registering on our website.
Language:
type: string
description: the language the customer picked during registration.