AWS Redshift
Bruin supports AWS Redshift as a data platform, which means you can use Bruin to build tables and views in your Redshift data warehouse.
Connection
In order to set up a Redshift connection, you need to add a configuration item to connections in the .bruin.yml file complying with the following schema Mind that, despite the connection being at all effects a Postgres connection, the default port field of Amazon Redshift is 5439.
connections:
redshift:
- name: "connection_name"
username: "awsuser"
password: "XXXXXXXXXX"
host: "redshift-cluster-1.xxxxxxxxx.eu-north-1.redshift.amazonaws.com"
port: 5439
database: "dev"
schema: "schema_name" # optional
ssl_mode: "allow" # optionalNOTE
ssl_mode should be one of the modes describe in the PostgreSQL documentation.
Making Redshift publicly accessible
Before the connection works properly, you need to ensure that the Redshift cluster can be accessed from the outside. In order to do that you must mark the configuration option in your Redshift cluster
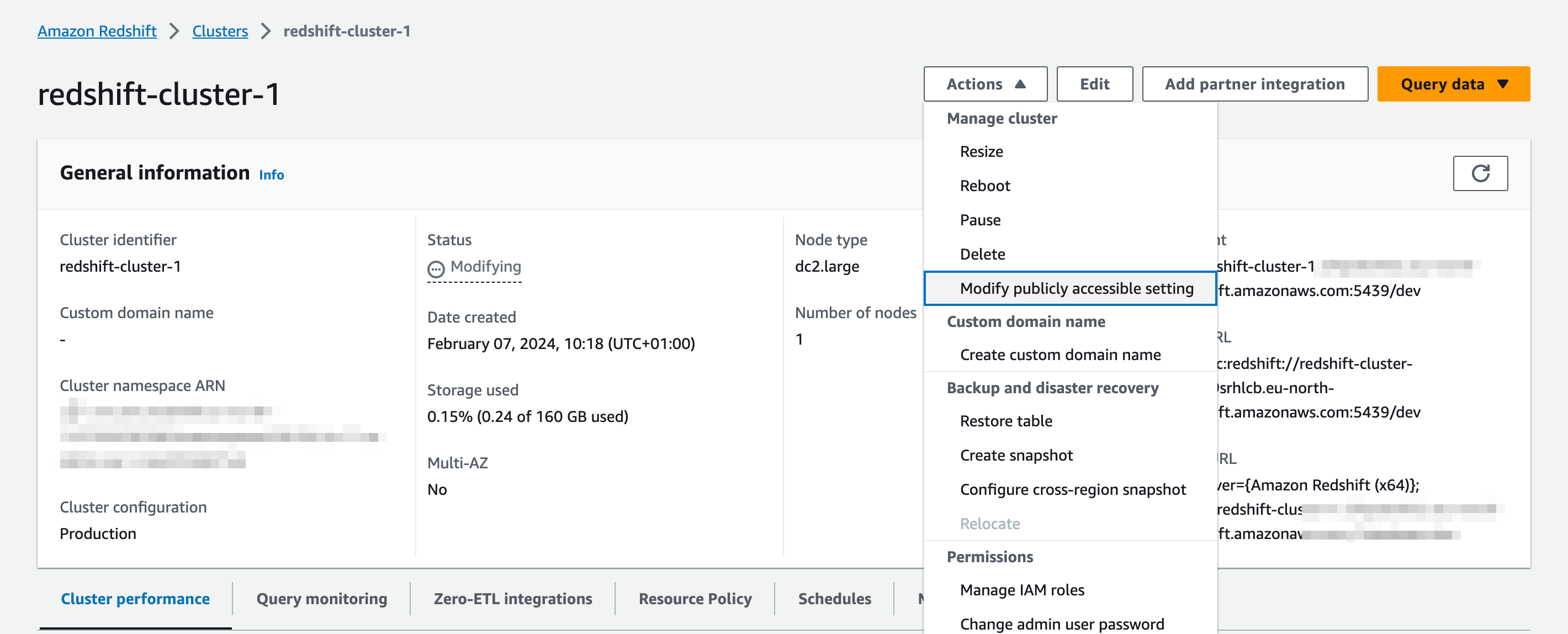
In addition to this, you must configure the inbound rules of the security group your Redshift cluster belongs to, to accept inbound connections. In the example below we enabled access for all origins but you can set more restrictive rules for this.
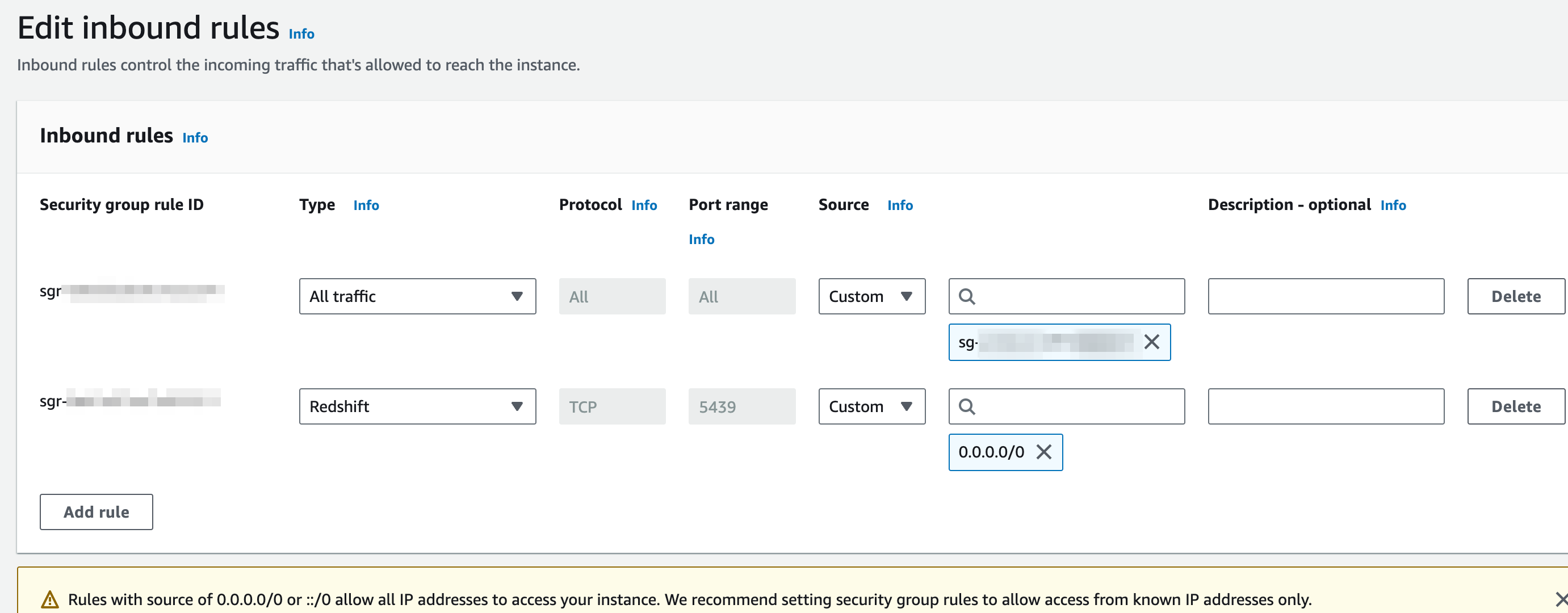
If you have trouble setting this up you can check AWS documentation on the topic
AWS Redshift Assets
rs.sql
Runs a materialized AWS Redshift asset or an SQL script. For detailed parameters, you can check Definition Schema page.
Example: Create a table for product reviews
/* @bruin
name: product_reviews.table
type: rs.sql
materialization:
type: table
@bruin */
create table product_reviews (
review_id bigint identity(1,1),
product_id bigint,
user_id bigint,
rating int,
review_text varchar(500),
review_date timestamp
);Example: Run an AWS Redshift script to clean up old data
/* @bruin
name: clean_old_data
type: rs.sql
@bruin */
begin transaction;
delete from user_activity
where activity_date < dateadd(year, -2, current_date);
delete from order_history
where order_date < dateadd(year, -5, current_date);
commit transaction;rs.sensor.query
Checks if a query returns any results in Redshift, runs every 5 minutes until this query returns any results.
name: string
type: string
parameters:
query: string
poke_interval: int (optional)
timeout: duration (optional)Parameters:
query: Query you expect to return any resultspoke_interval: The interval between retries in seconds (default 30 seconds).timeout: How long to wait before the sensor fails. Uses single-unit duration syntax (s,m,h,d,ms,ns), e.g.1hor90m. Defaults to24h. See Sensor Timeout.
rs.sensor.table
Sensors are a special type of assets that are used to wait on certain external signals.
Checks if a table exists in Redshift, runs by default every 30 seconds until this table is available.
name: string
type: string
parameters:
table: string
poke_interval: int (optional)
timeout: duration (optional)Parameters:
table:schema_id.table_idor (for default schemapublic)table_idformat.poke_interval: The interval between retries in seconds (default 30 seconds).timeout: How long to wait before the sensor fails. Uses single-unit duration syntax (s,m,h,d,ms,ns), e.g.1hor90m. Defaults to24h. See Sensor Timeout.
Example: Partitioned upstream table
Checks if the data available in upstream table for end date of the run.
name: analytics_123456789.events
type: rs.sensor.query
parameters:
query: select exists(select 1 from upstream_table where dt = "{{ end_date }}")Example: Streaming upstream table
Checks if there is any data after end timestamp, by assuming that older data is not appended to the table.
name: analytics_123456789.events
type: rs.sensor.query
parameters:
query: select exists(select 1 from upstream_table where inserted_at > "{{ end_timestamp }}")rs.seed
rs.seed is a special type of asset used to represent CSV files that contain data that is prepared outside of your pipeline that will be loaded into your Redshift database. Bruin supports seed assets natively, allowing you to simply drop a CSV file in your pipeline and ensuring the data is loaded to the Redshift database.
You can define seed assets in a file ending with .asset.yml or .asset.yaml:
name: dashboard.hello
type: rs.seed
parameters:
path: seed.csvParameters:
path: The path to the CSV file that will be loaded into the data platform. This can be a relative file path (relative to the asset definition file) or an HTTP/HTTPS URL to a publicly accessible CSV file.
WARNING
When using a URL path, column validation is skipped during bruin validate. Column mismatches will be caught at runtime.
Examples: Load csv into a Redshift database
The examples below show how to load a CSV into a Redshift database.
name: dashboard.hello
type: rs.seed
parameters:
path: seed.csvExample CSV:
name,networking_through,position,contact_date
Y,LinkedIn,SDE,2024-01-01
B,LinkedIn,SDE 2,2024-01-01rs.source
Defines Redshift source assets for documenting existing tables and views in your Redshift data warehouse. These assets are no-op (they don't execute), but are useful for:
- Documenting existing Redshift tables and views
- Adding column descriptions and metadata
- Establishing lineage relationships
- Query preview functionality in the VSCode extension
Example: Document an existing Redshift table
name: public.user_sessions
type: rs.source
description: "Tracks user session activity across the platform"
connection: redshift-default
tags:
- analytics
- user-behavior
domains:
- product
meta:
business_owner: "Product Analytics Team"
data_steward: "analytics@company.com"
refresh_frequency: "daily"
depends:
- public.users
columns:
- name: session_id
type: "VARCHAR(64)"
description: "Unique identifier for each user session"
- name: user_id
type: "INTEGER"
description: "Foreign key referencing the users table"
- name: started_at
type: "TIMESTAMP"
description: "Timestamp when the session began"
- name: ended_at
type: "TIMESTAMP"
description: "Timestamp when the session ended"
- name: device_type
type: "VARCHAR(50)"
description: "Type of device used during the session such as desktop, mobile, or tablet"